Code Review Bench
CRAVE — Code Review Automated Verification & Evaluation
A Comprehensive Benchmark for Evaluating LLM-Based Automated Code Review on Real-World Pull Requests
5,000+ review instances from 1,200+ repositories across 8 languages — measuring defect detection, security analysis, actionable feedback, and context-aware review quality.
Why Code Review Bench?
Moving beyond text-matching metrics to evaluate what actually matters in automated code review — real defect detection, actionable suggestions, and context awareness.
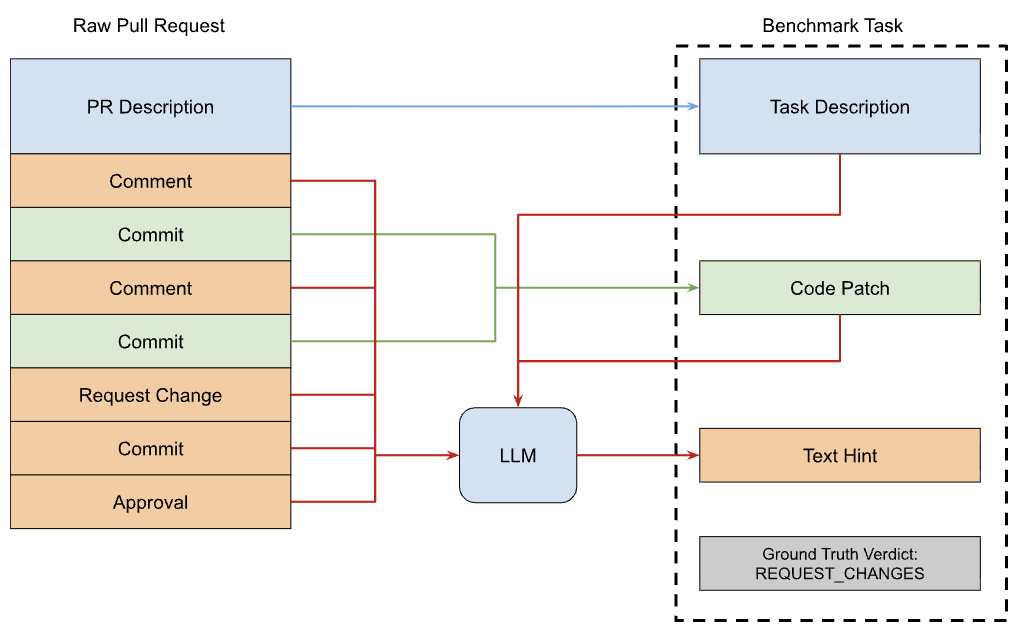
Real-World PR Reviews
Unlike synthetic benchmarks, every instance in Code Review Bench comes from actual pull request reviews with multi-round discussion between developers and maintainers.
Multi-Dimensional Scoring
Reviews are evaluated across 12 dimensions including defect detection, security analysis, code quality, actionability, and context awareness — not just textual similarity.
Repository-Level Context
Each review task includes full repository context — file dependencies, test suites, CI configurations, and project conventions — enabling evaluation of context-aware review capabilities.
Execution-Verified Reviews
Where applicable, review suggestions are verified through execution — ensuring that flagged defects are real and suggested fixes actually resolve the identified issues.
Review Dimensions
CRAVE evaluates automated code review across multiple critical dimensions that reflect real-world review quality.
Defect Detection
Identify logic errors, null pointer dereferences, race conditions, resource leaks, and other runtime defects from real-world pull requests.
Security Vulnerability Analysis
Detect injection flaws, authentication bypasses, insecure defaults, and OWASP Top 10 vulnerabilities in code changes.
Code Quality & Maintainability
Assess readability, adherence to coding standards, dead code, code duplication, and architectural anti-patterns in submitted diffs.
Actionable Feedback Generation
Evaluate whether review comments provide concrete, implementable suggestions rather than vague or generic observations.
Context-Aware Review
Measure how well models leverage repository context — file history, related modules, test coverage, and project conventions — when generating reviews.
Performance & Optimization
Identify algorithmic inefficiencies, unnecessary allocations, N+1 queries, and opportunities for caching or batching in submitted code.
Benchmark Construction Pipeline
A rigorous four-stage pipeline that transforms real pull request reviews into a structured, multi-dimensional evaluation benchmark.
PR Harvesting & Curation
Systematic collection of real pull requests from actively maintained open-source repositories. Each PR is filtered for review quality — requiring substantive reviewer comments, multi-round discussion, and concrete code changes resulting from the review process.
Review Decomposition
Each code review is decomposed into atomic review units — individual comments tied to specific code locations. Comments are classified by type (defect, style, security, performance, documentation) and severity to enable fine-grained evaluation.
Ground Truth Construction
Expert annotators verify and enrich each review unit with structured labels: issue category, severity, affected code range, expected fix pattern, and whether the comment led to an actual code change. This creates a multi-dimensional ground truth.
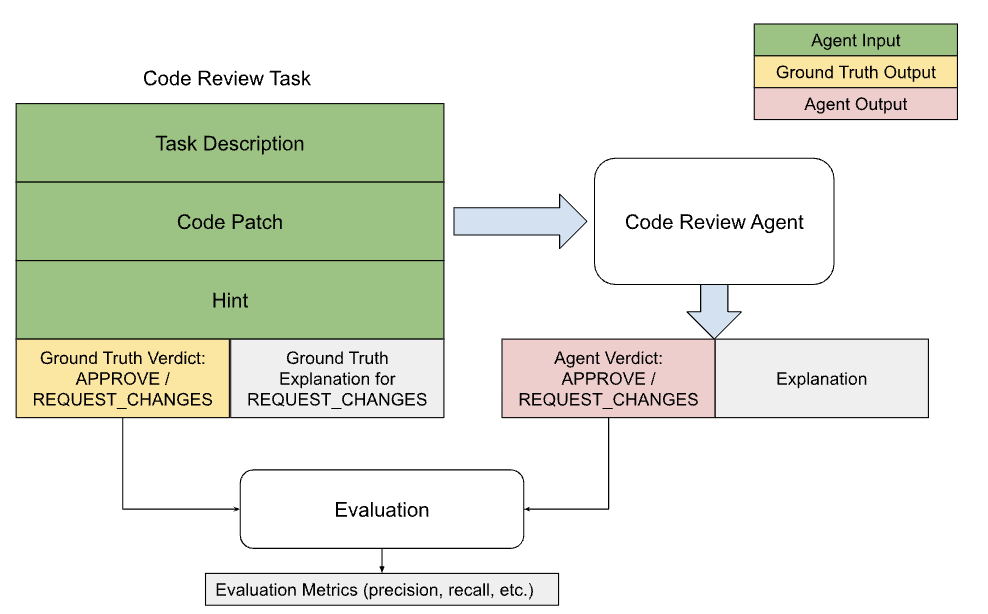
Automated Evaluation Framework
A multi-metric evaluation system scores model-generated reviews against ground truth across precision, recall, relevance, specificity, and actionability. Includes both automated metrics and LLM-judge alignment with human expert assessments.
Model Leaderboard
Performance of frontier LLMs on Code Review Bench — measuring precision, recall, and F1 for actionable defect identification.
Results measured on actionable defect identification across the full benchmark suite. Higher F1 indicates better balance between precision and recall.
Supported Languages
Who Uses Code Review Bench?
AI Labs
Evaluate and improve LLM-based code review capabilities. Benchmark new models against frontier performance on real-world review tasks.
DevTool Companies
Validate AI code review products against a standardized benchmark. Identify gaps in defect detection, security analysis, and actionable feedback generation.
Enterprise Teams
Benchmark internal AI-assisted code review tools. Measure review quality improvements before deploying to production workflows.
Frequently Asked Questions
Ready to Benchmark Your Code Review Model?
Request benchmark access, explore evaluation data, or discuss custom evaluation setups with our research team.